Machine Learning: Mit welchen Daten darf AI trainiert werden?
Dieser Beitrag beschäftigt sich mit Rechtsfragen, die beim Training von AI auftauchen und gibt einen Überblick über die anwendbaren europäischen und nationalen Rechtsgrundlagen.
In Anbetracht dessen, dass Large Language Models (im Folgenden auch: „LLM“) die Wahrscheinlichkeit von Wortfolgen vorhersagen sollen1 und auch andere AI-Anwendungen von umfassendem Trainingsmaterial profitieren, liegt es nahe, möglichst viele Inhalte als Trainingsgrundlage zu verwenden. Will man als Entwickler also das bestmögliche Ergebnis beim Training von AI erreichen, kann dies zu datenschutzrechtlichen, wettbewerbsrechtlichen und urheberrechtlichen Konflikten führen.
Im Dezember 2023 klagte2 die New York Times Microsoft und OpenAI aufgrund einer behaupteten Urheberrechtsverletzung. Im Zuge des Trainings von LLM seien urheberrechtlich geschützte Inhalte verwendet worden. Außerdem soll den Inhalten der Times, ob deren Qualität, im Vergleich zu anderen Inhalten beim Training von LLM besondere Beachtung geschenkt worden sein. Gefordert wird von der Times unter anderem die Vernichtung aller Chatbots und Trainingsdaten, die urheberrechtlich geschütztes Material der Times enthalten. Die Times betonte darüber hinaus ihre Unabhängigkeit und die daraus resultierende Bedeutung für die Demokratie sowie die Gefährlichkeit, die von Misinformation durch AI als Konkurrenz zur Times ausgehe.3
Das Verfahren findet vor dem United States District Court for the Southern District of New York in Manhattan, also einem Bundesbezirksgericht, statt, die New York Times hat die Verhandlung vor einer Jury beantragt. Das Verfahren ist noch anhängig.
Angesichts dieses Prozesses, dem weltweit voraussichtlich weitere folgen werden, wird in diesem Beitrag die, durch die Regelungen der EU geprägte, rechtliche Situation in Österreich dargestellt.
Der Fokus dieses Beitrags liegt auf datenschutzrechtlichen Aspekten im Zusammenhang mit AI und dient dazu, einen Überblick über die verschiedenen Rechtsgrundlagen zu erlangen, was angesichts der aktuellen Regelungsdichte keine ganz einfache Aufgabe ist.
Open Data
Der Grundgedanke: Offene Daten sind nicht geschützte, nicht personenbezogene Daten, die zur freien Nutzung, Weiterverbreitung und Weiterverwendung allen frei zur Verfügung stehen sollen.4
Diesen Grundgedanken hat die EU im Juni 2019 in eine Richtlinie gegossen:
Entsprechend der Richtlinie (EU) 2019/1024 des europäischen Parlaments und des Rates vom 20. Juni 2019 über offene Daten und die Weiterverwendung von Informationen des öffentlichen Sektors (Neufassung) (im Folgenden „PSI-RL“) können öffentliche Stellen gewisse Daten (näher dazu siehe Art 1 Abs 1 PSI-RL) zur Verfügung stellen.
Die Umsetzung der PSI-RL erfolgte in Österreich mit dem Bundesgesetz über die Weiterverwendung von Informationen öffentlicher Stellen, öffentlicher Unternehmen und von Forschungsdaten (Informationsweiterverwendungsgesetz 2022 – IWG 2022) BGBl. I Nr. 116/2022 (im Folgenden „IWG“). Es definiert in § 4 Z 20 IWG „offene Daten“ als „Dokumente in offenen Formaten, die von allen zu jedem Zweck frei verwendet, weiterverwendet und weitergegeben werden können“, in § 4 Z 6 IWG „Dokument“ als „jeder Inhalt unabhängig von der Form des Datenträgers […]“ oder als ein Teil eines solchen Inhalts.
Zu beachten ist allerdings die lange Liste an Ausnahmen in § 3 IWG, für die das IWG nicht gilt, allen voran Dokumente, die geistiges Eigentum Dritter betreffen sowie Dokumente, die von gewerblichen Schutzrechten erfasst werden, und Teile von Dokumenten, die dem Schutz der Privatsphäre und personenbezogener Daten unterliegen und dies nicht mit deren Weiterverwendung vereinbar ist.
Beispiele für offene Daten sind etwa Geodaten, Forschungsdaten oder Verkehrsinformationen. Sie sind bspw abrufbar unter https://www.data.gv.at/ oder https://www.opendataportal.at/infos/impressum/.
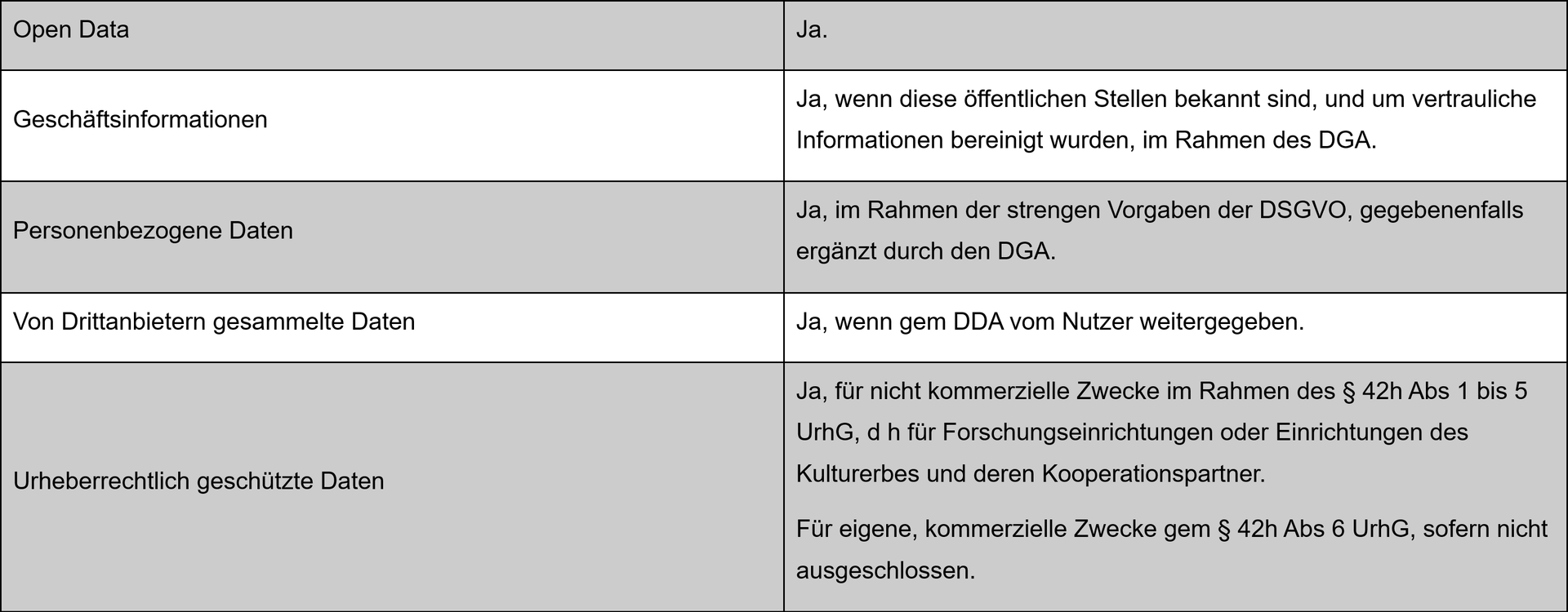
Open Data darf, kann und soll vielfältig verwendet werden, auch um AI zu trainieren.
Ein aktuelles Anwendungsbeispiel ist etwa die Hochwasser-Warn-App „PegelAlarm“ (https://earlyfloodalert.com/de/).5
Data Governance Act
Der Grundgedanke: Geschützte Daten, die eigentlich nicht beliebig zugänglich sind, können von öffentlichen Stellen zu deren Bedingungen zur Verfügung gestellt werden.6
Mit der am 03.06.2022 kundgemachten Verordnung (EU) 2022/868 des europäischen Parlaments und des Rates vom 30. Mai 2022 über europäische Daten-Governance und zur Änderung der Verordnung (EU) 2018/1724 (Daten-Governance-Rechtsakt) (im Folgenden „DGA“) trägt die EU dem enormen wirtschaftlichen und gesellschaftlichen Entwicklungspotenzial von Daten Rechnung. Deshalb will die EU den vertrauenswürdigen und sicheren Austausch von Daten ermöglichen und sicherstellen. Der DGA trat am 24.09.2023 in Kraft, Einrichtungen die bereits am 23.06.2022 Datenvermittlungsdienste erbrachten, müssen den entsprechenden Verpflichtungen ab dem 24.09.2025 entsprechen. Konkret sollen drei Ziele erreicht werden: 1. Regulierung der Weiterverwendung öffentlich gespeicherter geschützter Daten, 2. die Etablierung von Datenvermittlern, und 3. die Förderung der Datennutzung für altruistische Zwecke. Im Folgenden wird hauptsächlich auf die Weiterverwendung von Daten eingegangen.
Der DGA ermöglicht nicht nur, auf offene, also frei zugängliche Daten (siehe oben zu PSI-RL und IWG) zuzugreifen, sondern auch auf gesetzlich besonders geschützte. Art 3 DGA normiert vier Kategorien für Daten unter Bezugnahme auf den Schutzgrund: 1. geschäftliche Geheimhaltung, 2. statistische Geheimhaltung, 3. geistiges Eigentum Dritter, 4. personenbezogene Daten. „Daten“ meint gem Art 2 DGA „jede digitale Darstellung von Handlungen, Tatsachen oder Informationen sowie jede Zusammenstellung solcher Handlungen, Tatsachen oder Informationen auch in Form von Ton-, Bild- oder audiovisuellem Material“, mit anderen Worten also digitale Inhalte aller Art. Die Bestimmung der Bedingungen für die Gewährung des Zugangs zur Weiterverwendung von Daten überlässt der DGA den öffentlichen Stellen. Diese Bedingungen haben gemäß Art 5 DGA öffentlich zugänglich sowie nichtdiskriminierend, transparent, verhältnismäßig und objektiv gerechtfertigt zu sein, darüber hinaus dürfen die Bedingungen nicht der Behinderung des Wettbewerbs dienen. Diese Bedingungen könnten bspw die Einhaltung gewisser Sicherheitsstandards oder eine sichere Verarbeitungsumgebung sein. Ebenso haben öffentliche Stellen sicherzustellen, dass die Daten geschützt bleiben, personenbezogene Daten sind daher zu anonymisieren und vertrauliche Geschäftsinformationen, etwa Geschäftsgeheimnisse, oder geistiges Eigentum sind zu verändern, zu aggregieren oder aufzubereiten, sodass Personen nicht identifiziert werden können und keine vertraulichen Informationen offengelegt werden.
Zusätzlich werden Vereinbarungen, die ausschließliche Rechte zur Datenwiederverwendung gewähren, in Art 4 DGA grundsätzlich verboten, bzw nur zugelassen, wenn die Ausschließlichkeit erforderlich ist, um im allgemeinen Interesse liegende Dienste oder Produkte bereitzustellen und das exklusive Recht nicht länger als zwölf Monate besteht. Ein denkbares Beispiel könnte das Erstellen und entgeltliche Verfügbar-Machen von Statistiken sein. Natürlich entbindet die Erlaubnis zur Weiterverwendung der Daten aber nicht von der Einhaltung besonderer Schutzgesetze. Solche Schutzgesetze sind etwa die DSGVO und das Datenschutzgesetz, darüber hinaus sind in vielen weiteren Materiengesetzen Bestimmungen über den Umgang mit Daten enthalten.
Datenvermittlungsdienste dürfen Daten nicht für andere Zwecke verwenden, als sie Datennutzern verfügbar zu machen oder die Daten in einem anderen Format anzubieten. Außerdem sind angemessene technische, rechtliche und organisatorische Maßnahmen zu ergreifen, um die rechtswidrige Übertragung nicht personenbezogener Daten zu verhindern. Es kommt somit zur Ausweitung des Anwendungsbereiches von Art 32 DSGVO auf nicht personenbezogene Daten.7
Unter Datenaltruismus wird das freiwillige und unentgeltliche Einverständnis in die Verwendung der eigenen Daten verstanden. Gem Art 16 DGA dürfen Mitgliedstaaten mit organisatorischen oder technischen Regelungen Datenaltruismus erleichtern, insbesondere um betroffene Personen bei der Bereitstellung ihrer Daten, die im Besitz öffentlicher Stellen sind, zu unterstützen. Vorstellbar ist hier bspw, dass Patienten in öffentlichen Krankenhäusern erlauben, dass ihre Daten privaten Unternehmen zur Forschung zur Verfügung gestellt werden. Eine solche Erlaubnis könnte weitreichender sein als die oben diskutierten Zugangsmöglichkeiten.
Beispiele aus der Praxis sind unter anderem die finnische Sozial- und Gesundheitsdatenbehörde Findata, die Zugang zu den Daten der Sozialversicherungsträger sowie des Renten- und Bevölkerungsregisters gewährt, oder der französische Health Data Hub, der dem Unternehmen DAMAE Medical die Verbesserung seiner Hautkrebsdiagnose-Methode durch neue Trainingsdaten ermöglicht.8 Eines Umsetzungsgesetzes bedarf es grundsätzlich nicht, es handelt sich um eine unmittelbar anwendbare EU-Verordnung. Im Zuge des DGA wurde das Angebot der Statistik Austria um das sogenannte Austrian Micro Data Center („AMDC“) erweitert, das als Datenvermittlungsdienst fungiert. Das AMDC kann aber nur insoweit tätig werden, als die Daten diesem auch von den öffentlichen Stellen verfügbar gemacht werden.9
Der DGA kann also Grundlage sein, um an Daten zu gelangen, die für das Training von AI verwendet werden könnten, zu beachten ist jedoch, dass der DGA lediglich den Zugang regelt und sich die Verwendung nach anderen Normen bestimmt.
Digital Data Act
Der Grundgedanke: Es soll festgelegt werden, wer, unter welchen Bedingungen und auf welcher Grundlage, berechtigt ist, Produktdaten (eines Internet of Things-Produkts) oder verbundene Dienstdaten zu nutzen. Der Datenaustausch soll die Wettbewerbsfähigkeit erhöhen.10
Die Verordnung (EU) 2023/2854 des europäischen Parlaments und des Rates vom 13. Dezember 2023 über harmonisierte Vorschriften für einen fairen Datenzugang und eine faire Datennutzung sowie zur Änderung der Verordnung (EU) 2017/2394 und der Richtlinie (EU) 2020/1828 (Datenverordnung) (im Folgenden „DDA“) trat am 11.01.2024 in Kraft und wird umfassend ab dem 12.09.2025 anwendbar. Der DDA ist als Ergänzung und als „zweite Säule“ der europäischen Datenstrategie zu sehen, die „erste Säule“ ist der bereits besprochene DGA. Wurden im DGA Prozesse und Strukturen zum Datenaustausch geregelt, so stellt der DDA klar, wie die Wertschöpfung aus Daten erfolgt.
Der Adressatenkreis des DDA ist groß, er richtet sich an die Hersteller von vernetzten Produkten („Internet of Things-Produkte“), die Anbieter verbundener Dienste und deren Nutzer (das können juristische oder natürliche Personen sein), sowie an Dateninhaber und öffentliche Stellen. Ein verbundener Dienst ist gem Art 2 Z 3 DDA ein digitaler Dienst, einschließlich Software, der so in ein Produkt integriert ist, dass das Produkt ohne ihn seine Funktionen nicht ausführen könnte. Ein denkbares Beispiel ist etwa die Routenberechnung und Navigation, sowie die Bereitstellung von Karten mittels eines Servers der mit dem Navigationsgerät über das Internet kommuniziert.
Wesentlich sind etwa die Pflichten des Art 3 DDA: Vernetzte Produkte und verbundene Dienste, sind so zu konzipieren, dass dem Nutzer diese Daten einfach, sicher, unentgeltlich, in einem umfassenden, strukturierten, gängigen und maschinenlesbaren Format und, soweit relevant und technisch durchführbar, direkt zugänglich sind. Die EU normiert hier also den Gedanken des „Access by Design“, der Zugang zu Daten ist also ständig mitzudenken und keineswegs bloß nebensächlich. Zusätzlich gilt vor Abschluss eines Kauf-, Miet- oder Leasingvertrages eines Internet of Things-Produkts eine umfassende Informationspflicht hinsichtlich der gesammelten Daten, der Datensammelleistungsfähigkeit des Produkts, sowie des möglichen Zugangs zu den Daten.
Ebenso werden Daten- oder Diensteanbieter zur Interoperabilität von Daten, Mechanismen und Diensten zur Datenweitergabe verpflichtet. Dienste müssen also mit offenen Standards und Schnittstellen kompatibel sein, verschiedene Systeme müssen Daten austauschen können. Kunden muss der kostenlose Wechsel zwischen Datenverarbeitungsdiensten und die „Mitnahme“ ihrer Daten ermöglicht werden. Da der DDA vielfach das Vertragsrecht anpasst und ungewünschte Ungleichgewichte zwischen Vertragsparteien entschärfen soll11, können diese Rechte und Pflichten von Kunden vertraglich, von Mitgliedstaaten mittels Sanktionen, durchgesetzt werden. Es drohen, nach dem Vorbild der DSGVO, Geldstrafen bis zu 20 Mio. Euro oder vier Prozent des globalen Jahresumsatzes.12
Außerdem können sich Nutzer von Internet of Things-Produkten entscheiden, die gesammelten Daten mit Dritten zu teilen. Das soll den fairen Wettbewerb stärken und zur Verbesserung von Dienstleistungen führen.
Praktische Beispiele sind etwa das Verschieben von Daten von Cloud A zu Cloud B, wobei der Kunde keinen Widrigkeiten ausgesetzt sein darf, oder die Reparatur von Produkten durch Dritt-Anbieter unter Einbeziehung der gesammelten Daten.13
Denkbar ist, dass der Gedanke des Datenaltruismus des DGA erst durch den DDA und freigiebige Nutzer auflebt, indem diese, jene Daten, die verwendete Produkte und Dienste sammeln, teilen, und zur (Weiter-)Entwicklung von AI zur Verfügung stellen. Etwa könnten Nutzer eines Navigationsgeräts die über ihr Fahrverhalten gesammelten Daten unentgeltlich mit Entwicklern teilen, um die nächste Navigationssoftware zu verbessern.
Der DDA regelt primär die Weitergabe von Daten, sodass es Entwicklern einfacher möglich sein wird an Daten zum Training von AI zu gelangen. Die Frage wozu Daten verwendet werden dürfen, beantwortet der DDA allerdings nicht.
DSGVO
Der Grundgedanke: Daten mit Bezug zu Personen sind besonders schützenswert.
Die „Ur-Datenschutzvorschrift“ der EU, die Verordnung (EU) 2016/679 des europäischen Parlaments und des Rates vom 27. April 2016 zum Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten, zum freien Datenverkehr und zur Aufhebung der Richtlinie 95/46/EG (Datenschutz-Grundverordnung) (im Folgenden „DSGVO“) dürfte hinlänglich bekannt sein. Sie ist im Zusammenhang mit der Verwendung von Daten immer mitzudenken.
Zu beachten ist, dass personenbezogene Daten iSd DSGVO nicht nur jene Informationen sind die sich auf eine identifizierte natürliche Person beziehen, sondern auch jene Informationen mit denen eine natürliche Person identifizierbar ist. Kann also, bspw mit AI, anhand von (scheinbar) anonymisierten Daten Bezug zu einer natürlichen Person hergestellt werden, handelt es sich um personenbezogene Daten.
Auch gewährt bereits die DSGVO das Recht auf Auskunft und Datenübertragbarkeit und erlaubt die Verarbeitung der erhobenen Daten grundsätzlich nur für festgelegte, eindeutige und legitime Zwecke. Sollen personenbezogene Daten also verwendet werden um AI zu trainieren, so müssen alle betroffenen Personen darin einwilligen oder ein anderer Grund vorliegen, der die Verarbeitung erlaubt, etwa die notwendige Verarbeitung zur Wahrnehmung einer Aufgabe im öffentlichen Interesse (vgl Art 6 Abs 1 DSGVO). Sinnvollerweise ist hier vorsichtig zu agieren, könnten sich doch Daten als bloß scheinbar anonymisiert und tatsächlich, etwa durch die Anwendung der trainierten AI, als personenbezogen darstellen. Zu beachten ist, dass die genannten Normen, PSI-RL bzw IWG, DGA und DDA, die Anwendung der DSGVO keineswegs kategorisch ausschließen, sondern die jeweiligen Anwendungsbereiche und etwaige Überschneidungen zu beachten sind.
Die DSGVO erlaubt also die Verwendung von personenbezogenen Daten zum Training von AI unter gewissen strengen Voraussetzungen.
Urheberrecht
Der Grundgedanke: Geistige Schöpfungen sind nicht nur wertvoll, sondern werthaltig – ihre Verwertung bedarf besonderer Regeln.
Eigentümliche geistige Leistungen sind als Werke vom Urheberrechtsgesetz (im Folgenden „UrhG“) geschützt. Das Urheberrecht selbst ist höchstpersönlich und nicht übertragbar, es können nur Nutzungsrechte an Werken, sog Lizenzen eingeräumt werden. Freilich sind gerade urheberrechtlich geschützte Werke für das Training von AI höchst relevant, man denke nur an die Unmengen an (sinnvollerweise von Menschen produzierten!) Texten, anhand derer ein LLM lernt. Anders als menschliches Lernen kommt das Training von AI technisch nicht ohne Kopiervorgänge aus, weshalb es entsprechender urheberrechtlicher Befugnisse bedarf. Fraglich ist nun, ob das Training von AI im Wege der freien Werknutzung möglich ist und Lizenzkosten vermieden werden können.
Zu denken ist zunächst an eine bloß flüchtige oder begleitende Vervielfältigung, die in § 41a UrhG geregelt ist. Die Anwendung wird aber an folgenden Punkten scheitern: Einerseits setzt § 41a Z 3 UrhG die rechtmäßige Nutzung voraus – es bedarf also entweder einer Lizenz oder einer Regelung zur freien Werknutzung – und andererseits setzt § 41a Z 4 UrhG das Fehlen einer eigenständigen wirtschaftlichen Bedeutung der Vervielfältigung voraus. Das Training von AI mit Daten, also fremden Werken, bestimmt maßgeblich ihren wirtschaftlichen Wert, sodass die eigenständige wirtschaftliche Bedeutung gegeben sein wird.
Zusätzlich ist zweifelhaft, ob § 41a UrhG an sich auf das Training von AI anwendbar sein soll.14
Darüber hinaus ist die Richtlinie (EU) 2019/790 des europäischen Parlaments und des Rates vom 17. April 2019 über das Urheberrecht und die verwandten Schutzrechte im digitalen Binnenmarkt und zur Änderung der Richtlinien 96/9/EG und 2001/29/EG (im Folgenden „DSM-RL“) und ihre Umsetzung mit § 42h UrhG zu beachten. § 42h UrhG erlaubt die freie Werknutzung für Zwecke des Text- und Data-Minings. Die Regelung differenziert zwischen nicht kommerziellen Zwecken (§ 42h Abs 1 bis 5 UrhG) und eigenen, also auch kommerziellen, Zwecken (§ 42h Abs 6 UrhG). Hier eingegangen wird auf Letzteres.
Text- und Data-Mining ist in Art 2 Z 2 DSM-RL als „eine Technik für die automatisierte Analyse von Texten und Daten in digitaler Form, mit deren Hilfe Informationen unter anderem — aber nicht ausschließlich — über Muster, Trends und Korrelationen gewonnen werden können“ legaldefiniert. Die Definition wurde mit der Umsetzung im UrhG übernommen. Uneinigkeit besteht darüber, ob Text- und Data-Mining das Training von AI mitumfassen, die freie Werknutzung für Zwecke des Text- und Data-Minings also auf AI anwendbar sein soll. Manche differenzieren hier auch zwischen deskriptiver, prädiktiver und generativer AI.15 Mit der 2024 beschlossenen Verordnung (EU) 2024/1689 des europäischen Parlaments und des Rates vom 13. Juni 2024 zur Festlegung harmonisierter Vorschriften für künstliche Intelligenz und zur Änderung der Verordnungen (EG) Nr. 300/2008, (EU) Nr. 167/2013, (EU) Nr. 168/2013, (EU) 2018/858, (EU) 2018/1139 und (EU) 2019/2144 sowie der Richtlinien 2014/90/EU, (EU) 2016/797 und (EU) 2020/1828 (Verordnung über künstliche Intelligenz) (im Folgenden „AI Act“) konnte diese Frage wohl geklärt werden: Art 53 Abs 1 lit c AI Act nimmt explizit Bezug auf die Text- und Data-Mining-Regelung der DSM-RL, der EU-Gesetzgeber hat damit wohl klargestellt, dass AI-Training mitgemeint war und ist.16
Gem § 42h Abs 6 UrhG darf jedermann, also auch juristische Personen, auch zu kommerziellen Zwecken, alle Werke, zu denen rechtmäßig Zugang besteht für Zwecke des Text- und Data-Minings vervielfältigen, etwa also AI trainieren. Rechtmäßig zugänglich sind etwa alle lizenzierten Inhalte und, wie in ErwGr 14 DSM-RL erwähnt, alle im Internet frei verfügbaren Inhalte. Durch einen einseitigen Nutzungsvorbehalt durch den Rechteinhaber entfällt die Privilegierung.17
Zu beachten ist aber, dass § 42h UrhG die Speicherung der Vervielfältigungen nur so lange ermöglicht, wie es für den Zweck der Datenauswertung und Informationsgewinnung notwendig ist. Müssen oder sollen die Trainingsdaten langfristig gespeichert werden, bedarf es einer Klärung der Rechte.
Die urheberrechtlichen Anforderungen an das Training von AI sind somit streng, es empfiehlt sich die Lizenzierung.18 Es bleibt abzuwarten, ob und wie der EU-Gesetzgeber, der mit dem AI Act eine weltweite Vorreiterstellung eingenommen hat, auch das Urheberrecht an die zeitgenössischen technischen Entwicklungen anpasst.
Übersicht zu den Anwendungsbereichen
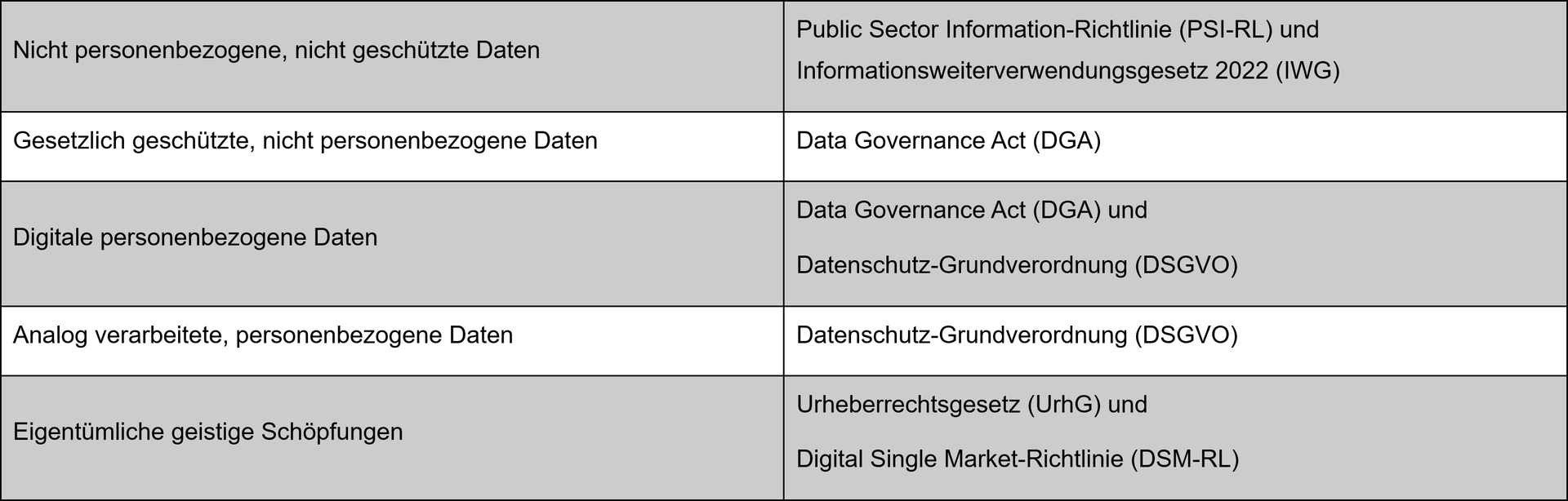
Mit welchen Daten darf AI nun trainiert werden?
1 Siehe Bowman, Eight Things to Know about Large Language Models (zuletzt aufgerufen am 09.04.2024 unter https://arxiv.org/abs/2304.00612).
2 Siehe unter https://www.nytimes.com/2024/03/04/technology/microsoft-ai-copyright-lawsuit.html#:~:text=The%20Times%20was%20the%20first,text%2C%20images%20and%20other%20media. sowie https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf; Case 1:23-cv-11195; (zuletzt abgerufen am 12.03.2024).
3 Siehe unter https://www.theguardian.com/media/2023/dec/27/new-york-times-openai-microsoft-lawsuit#:~:text=New%20York%20Times%20sues%20OpenAI%20and%20Microsoft%20for%20copyright%20infringement,-This%20article%20is&text=The%20New%20York%20Times%20has,billions%20of%20dollars%20in%20damages. (zuletzt aufgerufen am 12.03.2024).
4 Siehe Lutz, Open Data sorgenfrei publizieren, Dako 2015/36.
5 Siehe Hödl/ Rohrer, Open Data-Strategien für österreichische Gemeinden, RFG 2015/17.
6 Siehe Zimmer/Ginner in einem Positionspapier der Arbeiterkammer Wien aus 2020; https://www.arbeiterkammer.at/data-governance-act sowie https://wien.arbeiterkammer.at/service/studien/Konsument/Data_Governance_Act.pdf (zuletzt aufgerufen am 19.03.2024).
7 Siehe Knyrim, Der Data Governance Act und seine Schnittmenge mit der DSGVO, Dako 2023/29.
8 Siehe unter https://digital-strategy.ec.europa.eu/de/policies/data-governance-act-explained#ecl-inpage-l4iguon6 (zuletzt aufgerufen am 12.03.2024).
9 Siehe 14861/AB vom 14.08.2023 zu 15380/J (XXVII. GP), sowie https://www.statistik.at/fileadmin/announcement/2022/06/20220701AMDC.pdf und https://www.statistik.at/services/tools/services/center-wissenschaft/austrian-micro-data-center-amdc (zuletzt aufgerufen am 24.04.2024).
10 Vgl ErwGr 1 und 4 Digital Data Act.
11 Siehe Vorschlag des DDA, S 6 (zuletzt aberufen am 15.04.2024 unter https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=COM%3A2022%3A68%3AFIN).
12 Zum Ganzen Schürmann/Rosenthal/Dreyer Erfolg im digitalen Zeitalter: Der Data Act 2024 und seine Chancen für Ihr Unternehmen; siehe unter https://www.srd-rechtsanwaelte.de/blog/data-act-regelungen/ (zuletzt aufgerufen am 26.03.2024).
13 Siehe unter https://digital-strategy.ec.europa.eu/de/policies/data-act (zuletzt aufgerufen am 26.03.2024).
14 Riede/Hofer, Illegales Futter für künstliche Intelligenz, Der Standard 2023/06/01.
15 Vinazzer/Jakober, Nutzung urheberrechtlich geschützter Werke durch generative KI: aber nur mit Vergütung!, MR 2023 H 6 Beilage, 16.
16 Bernzen, Die KI-Verordnung: Außen Produktsicherheit, innen Urheberrecht, WRP 2024 H 4, I.
17 vgl § 42h Abs 6 zweiter Satz UrhG.
18 Ausführlich zum Ganzen und mit weiteren Nachweisen: Appl in Mayrhofer/Nessler/Bieber/Fister/Homar/Tumpel (Hrsg.) ChatGPT, Gemini & Co (2024) 69.